
Natural Language Processing (NLP) and Text Classification
Natural Language Processing (NLP)
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that focuses on the interaction between computers and humans through natural language. The goal of NLP is to enable computers to understand, interpret, and respond to human language in a way that is both meaningful and useful. NLP encompasses a variety of tasks, including but not limited to:
- Tokenization: Splitting text into individual words or tokens.
- Part-of-Speech Tagging: Identifying the grammatical parts of speech (nouns, verbs, adjectives, etc.) in a sentence.
- Named Entity Recognition (NER): Detecting and classifying named entities such as people, organizations, locations, dates, etc., within a text.
- Sentiment Analysis: Determining the sentiment or emotional tone of a piece of text.
- Machine Translation: Translating text from one language to another.
- Text Summarization: Condensing a long text into a shorter version while retaining the key information.
NLP combines computational linguistics, rule-based modeling of human language, and statistical, machine leaning, and deep learning models. It is widely used in various applications, including chatbots, virtual assistants, sentiment analysis in social media, and automated text summarization.
Text Classification
Text Classification is a specific task within NLP where the goal is to assign a text document, sentence, or word to one or more predefined categories. This task is crucial in many applications, such as spam detection, sentiment analysis, topic labeling, and language detection.
Steps in Text Classification
-
Data Collection: Gather labeled text data for training.
- Data Preprocessing: Clean and prepare the text data.
- Feature Extraction: Convert text into numerial features.
- Model Training: Train a machine learning model on the features.
- Model Evaluation: Assess the model's performance.
- Perdiction: Use the trained model to classify new text data.
Feature Extraction Techniques
Bag of Words (BoW)
Bag of Words (BoW) is a simple and commonly used feature extraction technique in text classification. In BoW:
- Each document is represented as a vector of word counts or frequencies.
- The order of words is ignored.
- It captures the presence or absence of words in the text.
For example, given two sentences:
- The cat sat on the mat.
- The dog sat on the mat.
The BoW representation might look like this:
[('the', 2), ('cat', 1), ('sat', 1), ('on', 1), ('mat', 1), ('dog', 1)]
N-grams
N-grams are continuous sequences of n items (words, characters, etc.) from a given text. They capture local word order information and are an extension of the BoW model. Common types include:
- Unigrams: Single words (n = 1).
- Bigrams: Pairs of consecutive words (n = 2).
- Trigrams: Triplets of consecutive words (n = 3).
For example, for the sentence "The cat sat":
- Unigrams: ["The", "cat", "sat"]
- Bigrams: ["The cat", "cat sat"]
- Trigrams: ["The cat sat"]
SpaCy
Spacy is an open-source software library for advanced natural language processing (NLP) in Python. It is designed specifically for production use and provides easy-to-use interfaces for training and deploying machine learning models for tasks such as named entity recognition, part-of-speech tagging, and text classification. SpaCy is known for its performance and efficiency in handling large volumes of text data.
Reference Respository
Imports and Setup
import spacy
import pandas as pd
import random
import time
import warnings
import life_style_tools
import Train
from spacy.cli.init_config import fill_config
from spacy.cli.train import train
from pathBuilder import PathBuilder
from tqdm import tqdm
warnings.filterwarnings('ignore')
We begin by importing the necessary libraries, including spaCy for NLP, pandas for data manipulation, and custom modules for specific funtionalities.
File Paths and Configuration
MedicalRecords = "smokers_surrogate_train_all_version2.xml"
TEST_MedicalRecords = "smokers_surrogate_test_all_groundtruth_version2.xml"
src = "/media/shumin/ssd2T/github/2006_Smoking_Status_Challenge/Medical-Record-Classifier/code/"
sample_amount = 10000
seed = 0
life_style = 'smoking'
optimize_for = 'efficiency'
path_builder = PathBuilder(optimize_for, life_style)
Specify the paths to the training and testing datasets. Additionally, set parameters such as the sample amount and seed for reproducibility.
Data Preparation
Load and Process Data
def getDataFrameFromRecords(record):
df = Train.GetJsonFromRecords(record)
df = Train.ColTransform(df)
df["smoking_unknown"] = df["smoking_status"].apply(Train.UnknownCol)
return df
training_pre = getDataFrameFromRecords(MedicalRecords)
testing_pre = getDataFrameFromRecords(TEST_MedicalRecords)
Load the medical records into dataframes and preprocess them, including transforming columns and handling unknown values.
Assign Labels
def assignLabel(df):
data_list = []
for i in range(len(df)):
data_dict = {}
if df['smoking_status'][i] == 'UNKNOWN':
data_dict['category'] = 'unknown'
elif df['smoking_status'][i] == 'NON-SMOKER':
data_dict['category'] = 'negative'
else:
data_dict['category'] = 'positive'
data_dict['text'] = Train.TextProcess(df['descrp'][i])
data_list.append(data_dict)
return data_list
training = assignLabel(training_pre)
testing = assignLabel(testing_pre)
Convert the smoking status column to categorical labels (positive, negative, unknown) and preprocess the text descriptions.
Model Training
random.Random(seed).shuffle(training)
life_style_tools.convert(training, "en", optimize_for, src)
fill_config(output_file = path_builder.get_en_config_path(), base_path = path_builder.get_en_base_config_path())
start = time.time()
train(config_path = path_builder.get_en_config_path(),
output_path = path_builder.get_en_test_model_path(),
overrides={"paths.train": path_builder.get_en_train_spacy_path(),
"paths.dev": path_builder.get_en_dev_spacy_path(),
"components.textcat.model.ngram_size": 2})
en_nlp = spacy.load(path_builder.get_en_test_model_best_path())
print("TRAINING TIME: ", time.time() - start)
Shuffle the training data, convert it to the required format, fill the configuration, and train the model. Measure the training time for efficiency.
Output
TRAINING
ℹ Saving to output directory:
en/efficiency/smoking/test/en_textcat_model
ℹ Using CPU
=========================== Initializing pipeline ===========================
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['textcat']
ℹ Initial learn rate: 0.001
E # LOSS TEXTCAT CATS_SCORE SCORE
--- ------ ------------ ---------- ------
0 0 0.22 11.42 0.11
0 200 44.23 49.71 0.50
1 400 36.51 55.94 0.56
1 600 18.74 56.45 0.56
2 800 20.67 57.02 0.57
3 1000 23.58 57.35 0.57
3 1200 20.34 60.90 0.61
4 1400 19.33 60.90 0.61
5 1600 20.67 61.75 0.62
5 1800 19.33 63.10 0.63
6 2000 17.33 63.10 0.63
6 2200 19.74 65.35 0.65
7 2400 14.39 72.49 0.72
8 2600 21.60 72.01 0.72
8 2800 13.30 75.99 0.76
9 3000 17.38 73.17 0.73
10 3200 13.34 74.80 0.75
10 3400 14.67 78.36 0.78
11 3600 13.33 80.10 0.80
12 3800 13.33 80.40 0.80
12 4000 13.82 82.06 0.82
13 4200 12.34 79.49 0.79
14 4400 11.39 81.85 0.82
14 4600 14.07 83.80 0.84
15 4800 8.63 82.65 0.83
16 5000 11.26 84.80 0.85
17 5200 10.77 85.51 0.86
17 5400 8.00 84.80 0.85
18 5600 6.67 84.11 0.84
19 5800 12.67 85.31 0.85
20 6000 7.33 85.42 0.85
20 6200 8.67 85.42 0.85
21 6400 11.98 85.10 0.85
22 6600 10.67 85.10 0.85
23 6800 9.33 85.10 0.85
✔ Saved pipeline to output directory
en/efficiency/smoking/test/en_textcat_model/model-last
TRAINING TIME: 99.28493309020996
The training process consists of multiple iterations where the loss decreases and the categorical score (CATS_SCORE) improves. This indicates that the model is learning effectively. The training process took approximately 99.28 seconds.
VALIDATION
ℹ Using CPU
================================== Results ==================================
TOK 100.00
TEXTCAT (macro F) 82.35
SPEED 883941
=========================== Textcat F (per label) ===========================
P R F
positive 85.54 88.75 87.12
negative 100.00 50.00 66.67
unknown 88.30 98.81 93.26
======================== Textcat ROC AUC (per label) ========================
ROC AUC
positive 0.95
negative 0.69
unknown 0.89
✔ Saved results to en/efficiency/metrics_en.json
\overline{AB}
The high F1 scores for positive and unknown labels indicate that the model performs well in these categories. However, the lower recall for the negative label suggests some challenges in identifying negative cases accurately.
ROC AUC
ROC (Receiver Operating Characteristic) AUC (Area Under the Curve). Those are performance measurement for classification problems. The ROC curve is a plot of true positive rate (sensitivity) against false positive rate (1 - specificity) at various threshold settings. The AUC represents the area under this curve and provides an aggregate measure of performance across all possible classification thresholds. An AUC of 1 indicates perfect classification, while an AUC of 0.5 suggests no discriminatory power.
Model Evaluation
def texting_evaluation(test_data, en_nlp):
label = 'category'
for i in tqdm(range(len(test_data))):
text = Train.TextProcess(test_data['text'][i])
test_data['processed'][i] = text
if test_data[label][i] == 'positive':
test_data['true'][i] = 1.0
elif test_data[label][i] == 'negative':
test_data['true'][i] = 0.0
else:
test_data['true'][i] = 2.0
doc = en_nlp(text)
tokens = [tok.text for tok in doc if tok.text not in (' ', '')]
test_data['tokenized'][i] = tokens
predict_cat = max(doc.cats, key=doc.cats.get)
test_data['predict'][i] = {'positive': 1.0, 'negative': 0.0, 'unknown': 2.0}[predict_cat]
test_data['possibility'][i] = doc.cats[predict_cat]
test_data['score'][i] = 1 if str(test_data['true'][i]) == str(test_data['predict'][i]) else 0
return test_data
testing = pd.DataFrame(testing)
testing['processed'] = ''
testing['true'] = ''
testing['predict'] = ''
testing['possibility'] = ''
testing['score'] = ''
testing['tokenized'] = ''
tested_data = texting_evaluation(testing, en_nlp)
print("Accuracy:", tested_data['score'].sum() / tested_data['score'].count())
Evaluate the trained model on the test data, processing each text and comparing the predicted labels with the true labels to calculate accuracy.
Output Analysis
Accuracy: 0.8366533864541833
The model achieved an accuracy of approximately 83.67% on the test data.
Calculate Metrics
from sklearn.metrics import accuracy_score, precision_score, f1_score
print('spacy_accuracy')
print(accuracy_score(list(tested_data['true'].values), list(tested_data['predict'].values)))
print('spacy_precision weighted')
print(precision_score(list(tested_data['true'].values), list(tested_data['predict'].values), average='weighted'))
print('spacy_f1_score weighted')
print(f1_score(list(tested_data['true'].values), list(tested_data['predict'].values), average='weighted'))
Output
spacy_accuracy
0.8366533864541833
spacy_precision weighted
0.8558293309169264
spacy_f1_score weighted
0.819599263711397
These metrics indicate the model's performance. The precision is higher than the accuracy, suggesting the model is more precise in its predictions. The F1 score, which balances precision and recall, is also reasonably high.
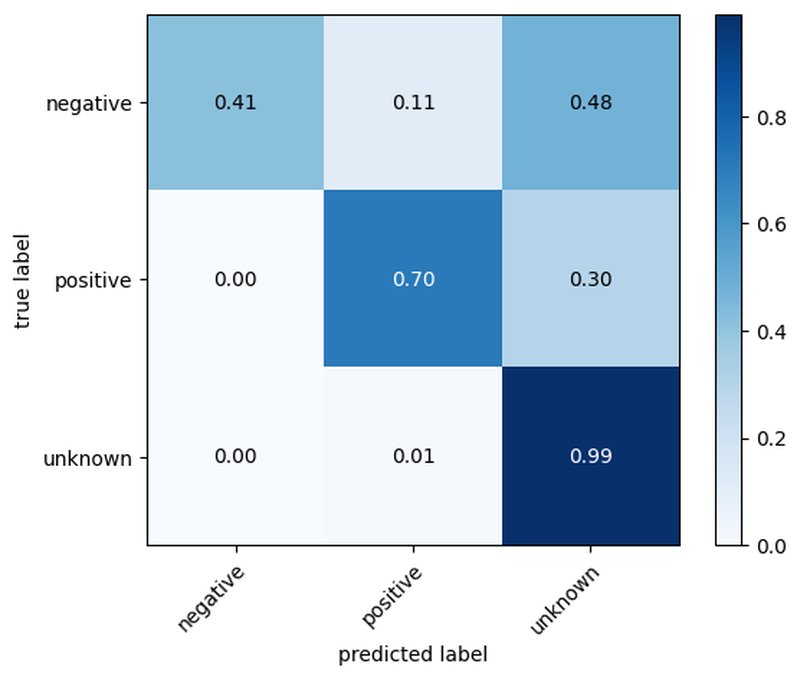
Confusion Matrix
from sklearn.metrics import confusion_matrix
from mlxtend.plotting import plot_confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(list(tested_data['true'].values), list(tested_data['predict'].values))
classes = ['negative', 'positive', 'unknown']
figure, ax = plot_confusion_matrix(conf_mat = cm,
class_names = classes,
show_absolute = False,
show_normed = True,
colorbar = True)
plt.show()
Generate and plot a confusion matrix to visualize the model's performance across different categories.
Save and Load Model
Save Model
import pickle
with open("life_style_en_model_20240509.pkl", "wb") as f:
pickle.dump(en_nlp, f)
Load Model
test_model = pd.read_pickle("life_style_en_model_20240509.pkl")
Conclusion
This workflow demonstrates the steps to train, evaluate, and save a SpaCy text classification model for classifying medical records based on smoking status. The model achieves high accuracy, precision, and recall for most categories, making it a reliable tool for this classification task. The analysis of the training ouput provides insights into the model's learning progress and final performance.


Comments...
No Comments Yet...