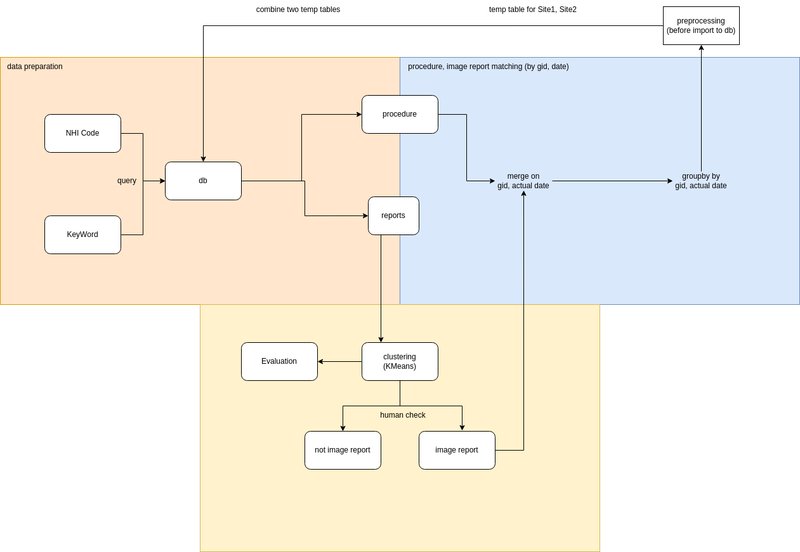
# ----------------------------data split-----------------------------------------------------------------------------
import time
start = time.time()
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC, SVC
from sklearn.linear_model import SGDClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
from sklearn.metrics import accuracy_score
from nltk.corpus import stopwords
import string
import re
from sklearn.utils import shuffle
import spacy
# stopwords = stopwords.words('english')
spacy.load('en_core_web_sm')
from spacy.lang.en import English
parser = English()
# parser = spacy.load('en_core_web_sm') # parser改成這樣,accuracy不變,用'en_core_web_md'、'en_core_web_lg'、'xx_ent_wiki_sm'(多語言)也不變
image = procedure_lab_merge
sample_size = int(image.shape[0] / 10)
image = image.sample(n = sample_size)
index = image.index
image = shuffle(image)
# image.index = index
# image = image[['json_text', 'categories']]
# ----------------------------for preprocessing-----------------------------------------------------------------------------
STOPLIST = set(stopwords.words('english') + list(ENGLISH_STOP_WORDS))
SYMBOLS = " ".join(string.punctuation).split(" ") + ["-", "...", "”", "”"]
def cleanText(text):
text = text.replace('paragraph', '').replace(':', '').replace('<br>', '')\
.replace('"', '').replace(',', '').replace('{', '').replace('}', '').replace('\n', '')\
.replace('\\', '').replace('[', '').replace(']', '').replace('(', '').replace(')', '')
# text = text.strip().replace("\n", " ").replace("\r", " ")
text = text.lower()
return text
# 去除'paragraph:'後,accuracy提昇很多,去除符號幾乎沒有影響
# lower, lemmatization & stopwords
def tokenizeText(sample):
tokens = parser(sample)
tokens = [tok for tok in tokens if tok.text not in STOPLIST]
tokens = [tok.text for tok in tokens if tok.text not in SYMBOLS]
tokens = ' '.join(tokens)
return tokens
image['tokenized'] = ''
image['tokenized'] = image['json_text_y'].map(lambda x: tokenizeText(cleanText(x)))
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfconvert = TfidfVectorizer(analyzer=tokenizeText, ngram_range=(1,3)).fit(image['tokenized'])
len(tfidfconvert.vocabulary_)
X_transformed = tfidfconvert.transform(image['tokenized'])
print(time.time() - start)
import time
start = time.time()
from sklearn.cluster import KMeans
from sklearn.metrics import roc_auc_score
# Can unsupervised learning(no true label) perform ROC, AUC?
modelkmeans = KMeans(n_clusters = 40, random_state = 42, max_iter = 8).fit(X_transformed)
kmeans_cat_2 = modelkmeans.predict(X_transformed)
# print(roc_auc_score(kmeans_cat)) # TypeError: roc_auc_score() missing 1 required positional argument: 'y_score'
# n = 100, 27
# n = 1000, 36
# print(len(set(kmeans_cat)))
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state = 42)
reduced_features = pca.fit_transform(X_transformed.toarray())
reduced_cluster_centers = pca.transform(modelkmeans.cluster_centers_)
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 20))
# plt.ylim(-0.2, 0.3)
plt.scatter(reduced_features[:,0], reduced_features[:,1], c=modelkmeans.predict(X_transformed))
# ax.show()
# plt.scatter(reduced_cluster_centers[:,0], reduced_cluster_centers[:,1], marker='x', s=150, c='b')
from sklearn.metrics import silhouette_score
print('silhouette_score: ', silhouette_score(X_transformed, labels=modelkmeans.predict(X_transformed)))
# from sklearn import metrics
# print('calinski_harabasz_score: ', metrics.calinski_harabasz_score(X_transformed.toarray(), modelkmeans.predict(X_transformed.toarray())))
# from sklearn.metrics import davies_bouldin_score
# print('davies_bouldin_score: ', davies_bouldin_score(X_transformed.toarray(), modelkmeans.predict(X_transformed.toarray())))
# from scipy.spatial.distance import cdist
print('clustering time: ', time.time() - start)
import time
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# Start timing
start = time.time()
# Clustering with KMeans
modelkmeans = KMeans(n_clusters=40, random_state=42, max_iter=8).fit(X_transformed)
kmeans_labels = modelkmeans.predict(X_transformed)
# Dimensionality reduction with t-SNE
tsne = TSNE(n_components=2, random_state=42, perplexity=30, n_iter=1000, learning_rate=200)
reduced_features_tsne = tsne.fit_transform(X_transformed.toarray())
# Plotting the results
plt.figure(figsize=(20, 20))
plt.scatter(reduced_features_tsne[:, 0], reduced_features_tsne[:, 1], c=kmeans_labels, cmap='viridis', s=10)
plt.colorbar(label='Cluster Label')
plt.title("t-SNE Visualization of KMeans Clustering", fontsize=18)
plt.xlabel("t-SNE Component 1")
plt.ylabel("t-SNE Component 2")
plt.show()
# Clustering evaluation
print('Silhouette Score:', silhouette_score(X_transformed, labels=kmeans_labels))
print('Clustering Time:', time.time() - start)



Comments...
No Comments Yet...